Getting Started
Use the Connector in Your Project
Option 1: Maven Central Repository

Edit File pom.xml
Copy and paste the following Maven Dependency into your Mule application pom file.
<dependency>
<groupId>io.github.mulesoft-ai-chain-project</groupId>
<artifactId>mule4-webcrawler-connector</artifactId>
<version>{version}</version>
<classifier>mule-plugin</classifier>
</dependency>Option 2: Local Maven Repository
System Requirements
Before you start, ensure you have the following prerequisites:
- Java Development Kit (JDK) 11 and 17
- Apache Maven
- MuleSoft Anypoint Studio
Download the MuleSoft WebCrawler Connector
Clone the MuleSoft WebCrawler Connector repository from GitHub:
git clone https://github.com/MuleSoft-AI-Chain-Project/mule-webcrawler-connector.git
cd mule-webcrawler-connectorBuild the Connector with Java 11, 17, 21, 22, etc.
Step 1
export MAVEN_OPTS="--add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.util.regex=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.xml/javax.xml.namespace=ALL-UNNAMED"Step 2
For Java 17
mvn clean install -Dmaven.test.skip=true -DskipTests -Dgpg.skip -Djdeps.multiRelease=17
For Java 21
mvn clean install -Dmaven.test.skip=true -DskipTests -Dgpg.skip -Djdeps.multiRelease=21
For Java 22
mvn clean install -Dmaven.test.skip=true -DskipTests -Dgpg.skip -Djdeps.multiRelease=22The MAC Project connectors are constantly updated, and the version is regularly changed.
Make sure to replace {version} with the latest release from our GitHub repository (opens in a new tab).
Add the following dependency to your pom.xml file:
<dependency>
<groupId>com.mulesoft.connectors</groupId>
<artifactId>mule4-webcrawler-connector</artifactId>
<version>{version}</version>
<classifier>mule-plugin</classifier>
</dependency>Connector Configuration
The configuration is applicable to the Crawl and Page operations
The configuration for the MuleSoft WebCrawler connector is simple to create.
Go to the Global Elements in your MuleSoft project, and create a new configuration. In the Connector Configuration, you will find the MuleSoft WebCrawler Connector Config. Select it and press OK.
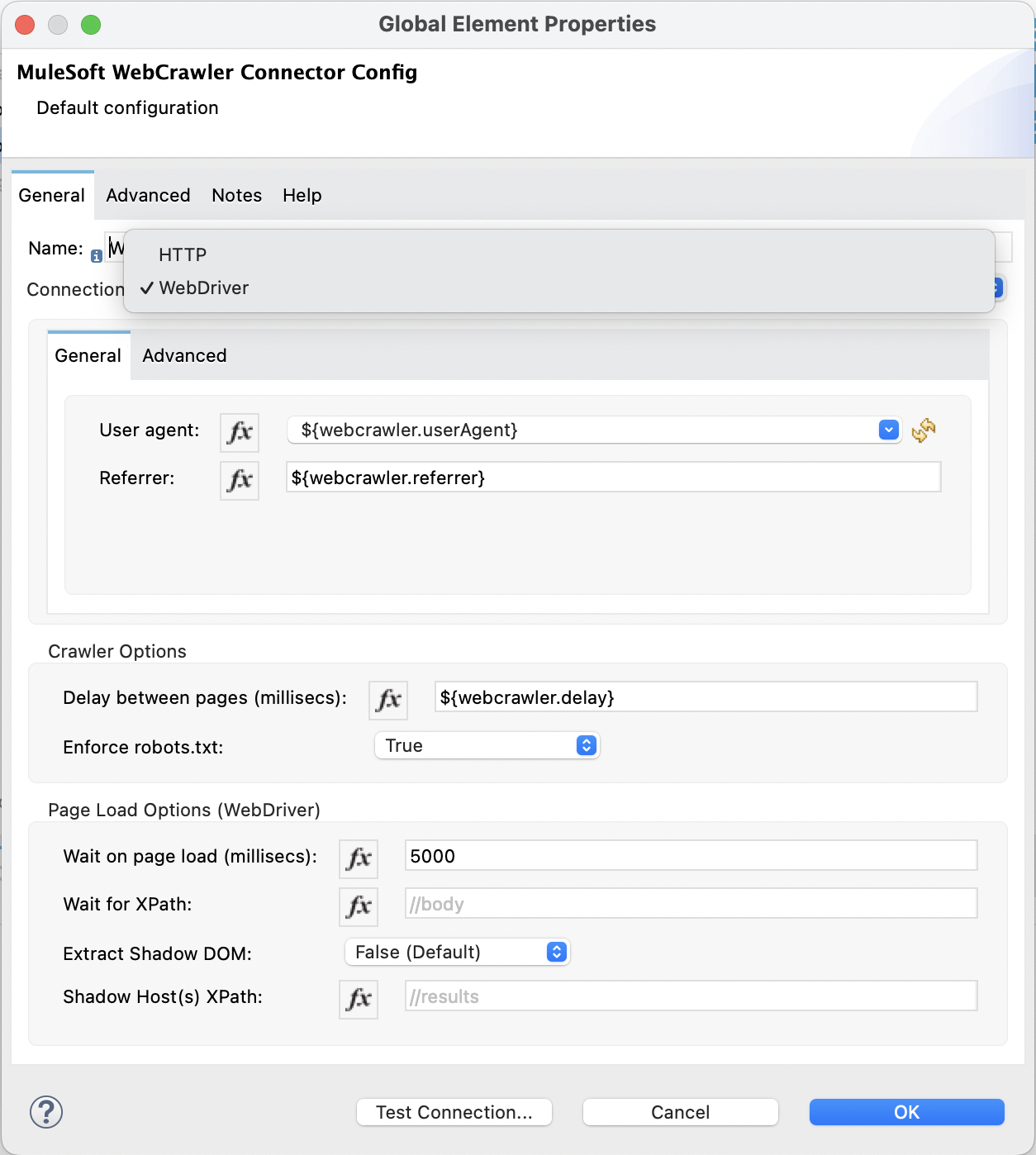
Connection
- HTTP: Using an http client for static content retrieval.
- User agent: The user agent to use for the request.
- Referrer : The referrer to use for the request (not set during dynamic content retrieval).
- Timeout: The timeout for the request in milliseconds.
- Web Driver : Using Selenium WebDriver for dynamic content retrieval.
- User agent: The user agent to use for the request.
- Referrer : The referrer to use for the request (not set during dynamic content retrieval).
Crawler Options
- Delay (millisec): The delay between page requests in milliseconds.
- Enforce robots.txt: Enforce robots.txt rules.
Page Load Options (WebDriver)
Page load options only applies to the WebDriver connection. They make sense only in case of dynamic content retrieval.
- Wait on page load (millisec): The time to wait for the page to load in milliseconds.
- Wait for XPath: The XPath to wait for before continuing. The process continue in any case once the
Wait on page load (millisec)is reached. - Extract Shadow DOM: Extract the shadow DOM content.
- Shadow Host(s) XPath: The XPath to the shadow host(s) to extract. If not set, the whole shadow DOM is extracted.
If set all the shadow DOM nested inside the
shadow host(s)is extracted and the content is merged in the order they appear in the page.
Deployment and Troubleshooting
Deploying to CloudHub and Cloudhub 2.0
In order for dynamic content retrieval to work in CloudHub based deployments, you will need
to set the cloudhub.deployment property to true.
This can be done either via an application property in Runtime Manager, or in your CloudHub deployment
configuration in your pom.xml.
This property will allow the installation of Chrome at runtime into your CloudHub worker VM, along with necessary dependencies.
The Chrome instance runs separately from the JVM, and as such, trying to crawl significantly large pages with the wrong worker size may trigger memory related issues (opens in a new tab), such as the JVM or CloudHub worker getting terminated and/or restarted.
To track how much memory is being consumed by the JVM and overall worker, you can set cloudhub.deployment.memoryMonitor to true. This will periodicially log memory
metrics that can aid in troubleshooting and determine the appropriate sizing for your needs.