Page Operations
Page | Download Document
The Download document operation allows you download documents from a specified webpage. You can also use it to
download a single document by providing it the direct url of the document.
Input Fields
General
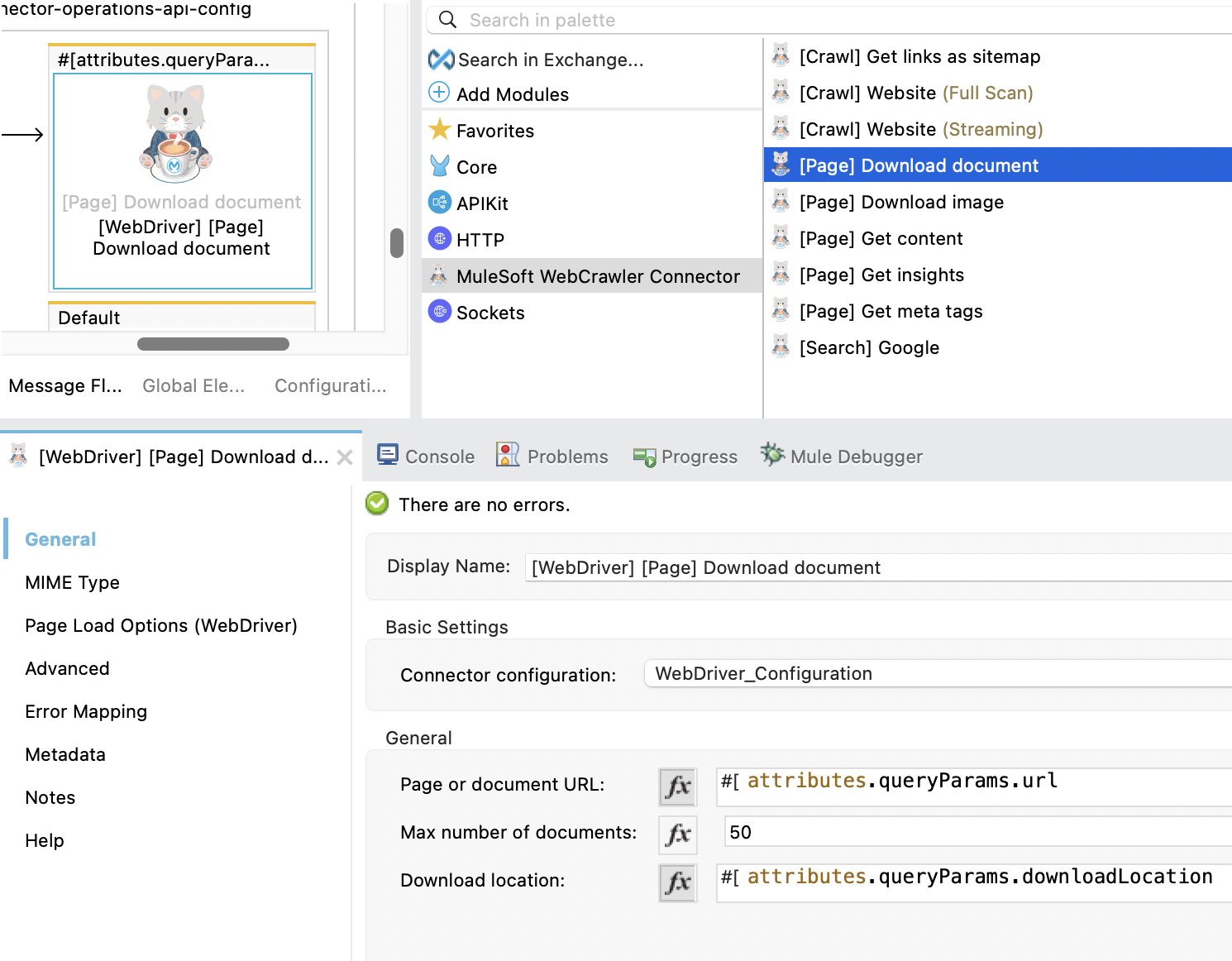
- Page or image URL: Specify the webpage url that contains the images you wish to download. This will download all images found on the webpage. Alternatively, you can provided a direct link to the image if you want to download a single image only.
- Max document number : The maximum number of document to be downloaded.
- Download location : The path where the crawler will download images to.
Page Load Options (WebDriver)
Page load options only applies to the WebDriver connection. They make sense only in case of dynamic content retrieval.
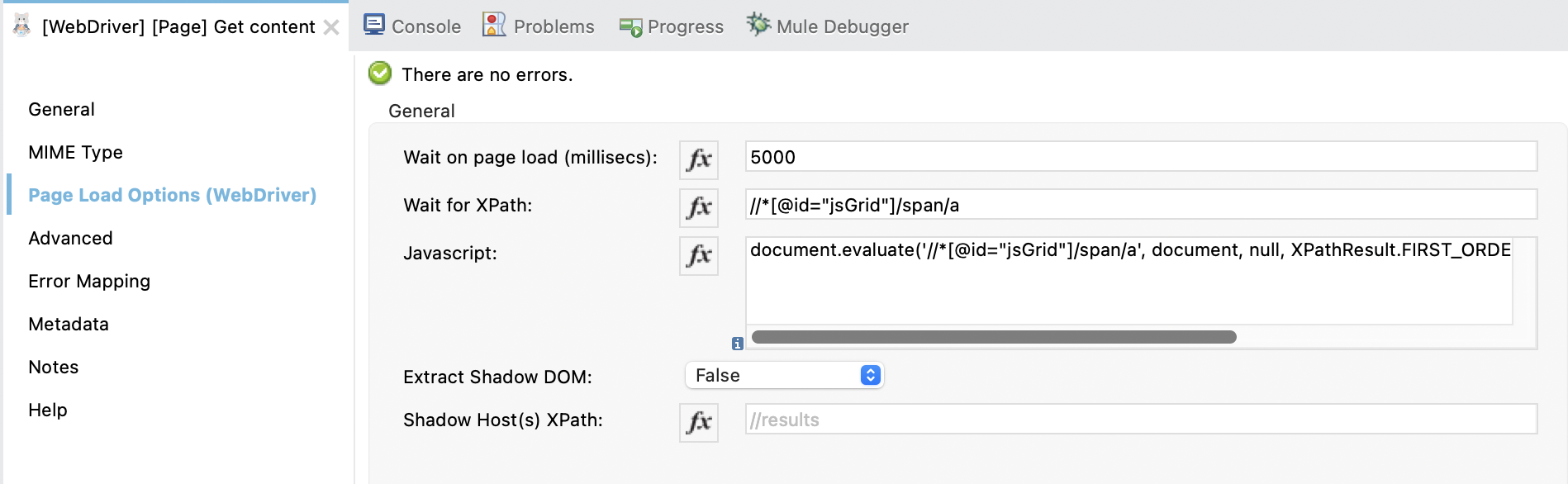
- Wait on page load (millisec): The time to wait for the page to load in milliseconds.
- Wait for XPath: The XPath to wait for before continuing. The process continue in any case once the
Wait on page load (millisec)is reached. - Javascript: The javascript to execute on the page. The javascript is executed after the page is loaded and before the shadow DOM is extracted.
- Extract Shadow DOM: Extract the shadow DOM content.
- Shadow Host(s) XPath: The XPath to the shadow host(s) to extract. If not set, the whole shadow DOM is extracted.
If set all the shadow DOM nested inside the
shadow host(s)is extracted and the content is merged in the order they appear in the page.
XML Configuration
Below is the XML configuration for this operation:
<mac-web-crawler:page-download-document
doc:name="[Page] Download document"
doc:id="426d217d-74c5-4c9d-9bdb-74f075fc1f26"
url="#[payload.url]"
downloadPath="#[payload.downloadLocation]"
maxDocumentNumber="50"/>Output Fields
Payload
This operation responds with a json payload.
Example
[
{
"fileName": "versioning-back-support-policy.pdf",
"mimeType": "application/pdf",
"url": "https://www.salesforce.com/content/dam/web/en_us/www/documents/legal/Agreements/versioning-back-support-policy.pdf"
}
]Page | Download Image
The Download image operation allows you download images from a specified webpage. You can also use it to download a single image by providing it the direct url of the image.
Input Fields
General
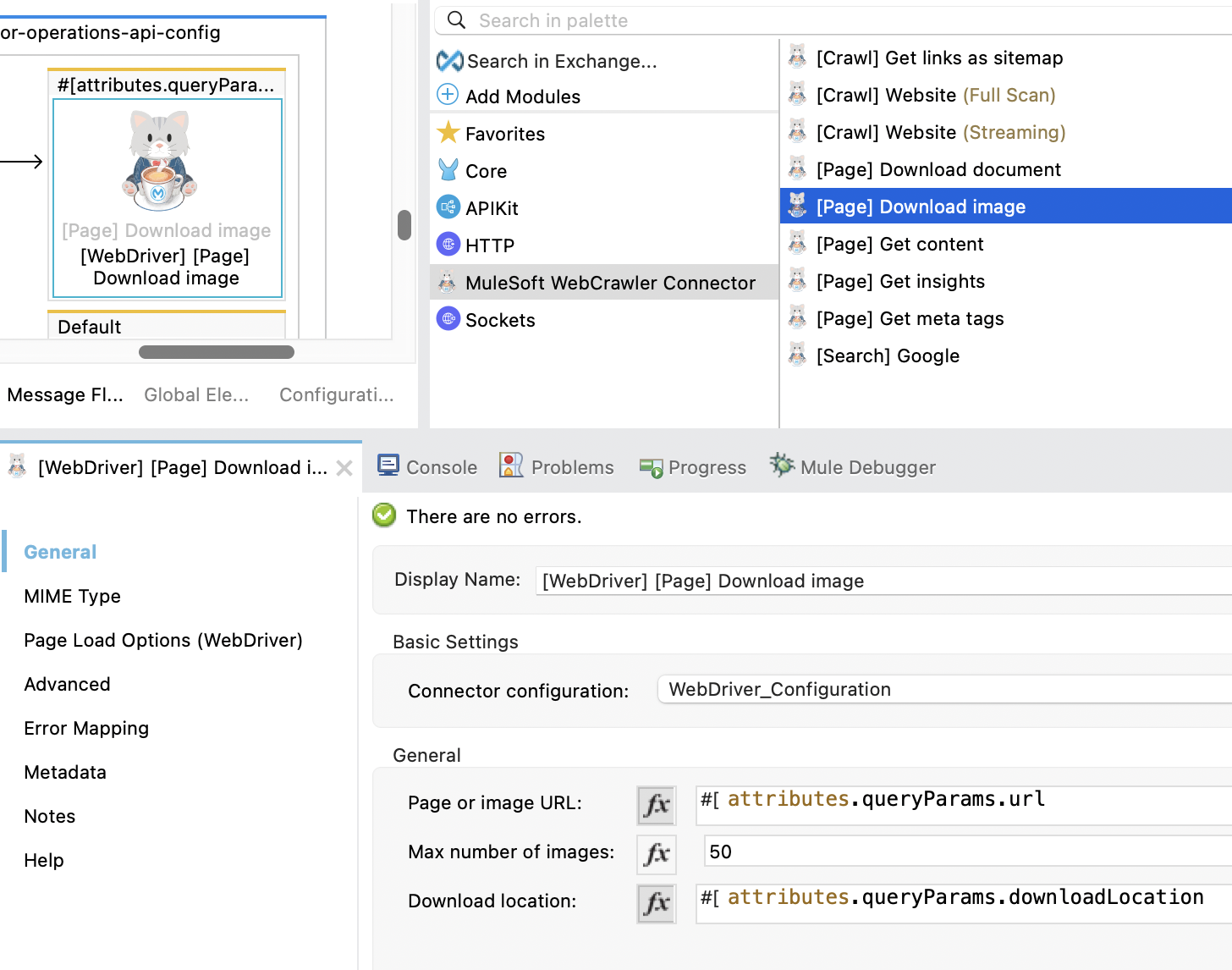
- Page or image URL: Specify the webpage url that contains the images you wish to download. This will download all images found on the webpage. Alternatively, you can provided a direct link to the image if you want to download a single image only.
- Max image number : The maximum number of image to be downloaded.
- Download location : The path where the crawler will download images to.
Page Load Options (WebDriver)
Page load options only applies to the WebDriver connection. They make sense only in case of dynamic content retrieval.
- Wait on page load (millisec): The time to wait for the page to load in milliseconds.
- Wait for XPath: The XPath to wait for before continuing. The process continue in any case once the
Wait on page load (millisec)is reached. - Javascript: The javascript to execute on the page. The javascript is executed after the page is loaded and before the shadow DOM is extracted.
- Extract Shadow DOM: Extract the shadow DOM content.
- Shadow Host(s) XPath: The XPath to the shadow host(s) to extract. If not set, the whole shadow DOM is extracted.
If set all the shadow DOM nested inside the
shadow host(s)is extracted and the content is merged in the order they appear in the page.
XML Configuration
Below is the XML configuration for this operation:
<mac-web-crawler:page-download-image
doc:name="[Page] Download image"
doc:id="426d217d-74c5-4c9d-9bdb-74f075fc1f26"
url="#[payload.url]"
downloadPath="#[payload.downloadLocation]"
maxImageNumber="50"/>Output Fields
Payload
This operation responds with a json payload.
Example
[
{
"fileName": "mulechain-project-desc.97862945.png",
"mimeType": "image/png",
"url": "https://mac-project.ai/_next/image?url=%2F_next%2Fstatic%2Fmedia%2Fmulechain-project-desc.97862945.png&w=3840&q=75"
},
{
"fileName": "mulechain-project-model-support.1411a98a.png",
"mimeType": "image/png",
"url": "https://mac-project.ai/_next/image?url=%2F_next%2Fstatic%2Fmedia%2Fmulechain-project-model-support.1411a98a.png&w=3840&q=75"
},
{
"fileName": "mulechain-crawler-logo.png",
"mimeType": "image/png",
"url": "https://mac-project.ai/_next/image?url=%2Flogos%2Fmulechain-crawler-logo.png&w=128&q=75"
},
...
]Page | Get Content
Allows you to retrieve the contents of a specified webpage.
Input Fields
Module Configuration
This refers to the MuleSoft Web Crawler Configuration set up in the Getting Started section.
General
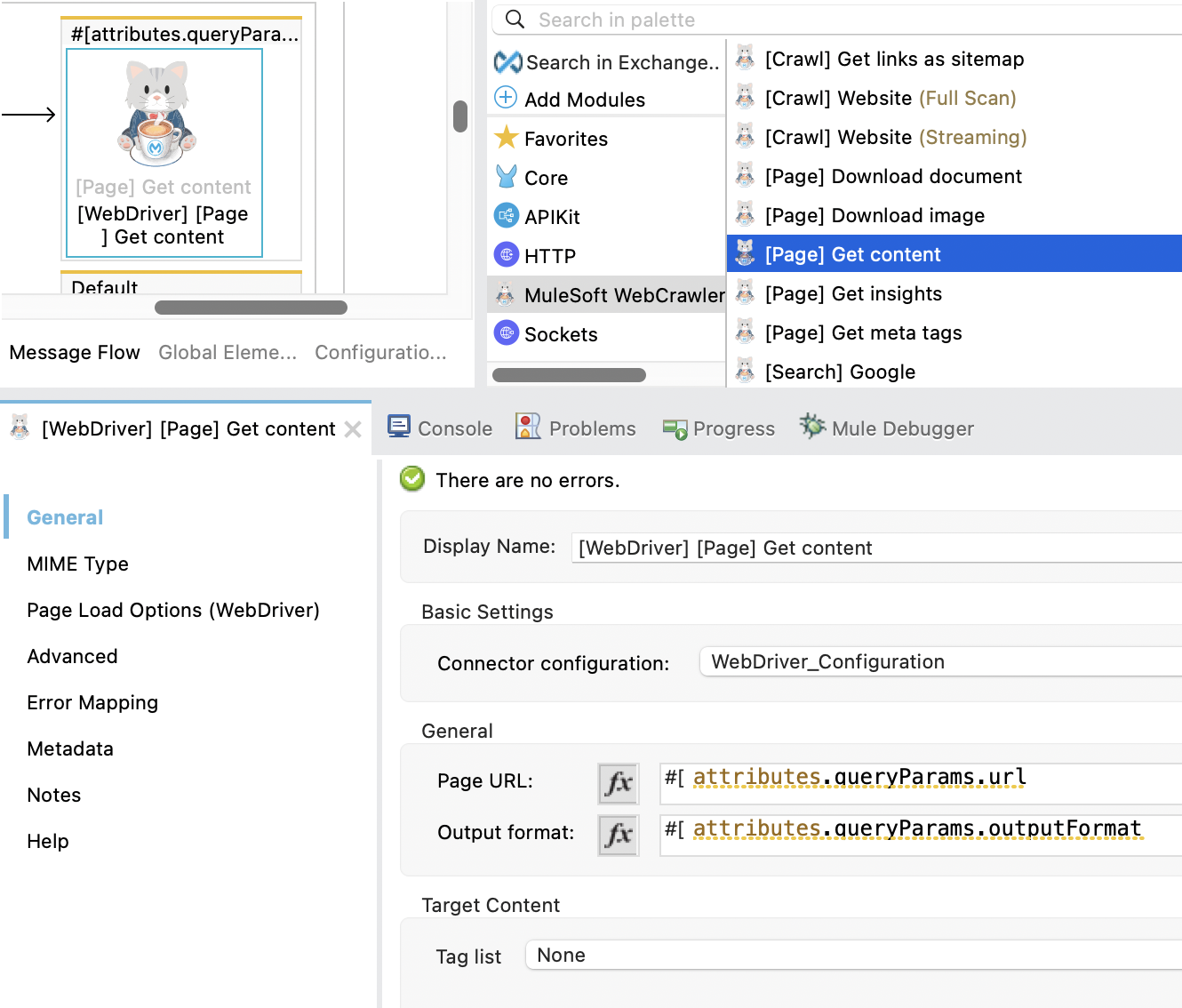
- Page URL: The webpage to fetch the contents for.
- Output format: The format of the output.
- HTML: The output will be in HTML format.
- TEXT: The output will be in TEXT format.
- MARKDOWN: The output will be in MARKDOWN format.
Target Content
- Tag list: An ordered list of CSS selectors (tags) for content extraction. The crawler will use the HTML content from the first selector that matches an element on the page. If there are no matches, the full HTML of the page will be extracted.
Page Load Options (WebDriver)
Page load options only applies to the WebDriver connection. They make sense only in case of dynamic content retrieval.
- Wait on page load (millisec): The time to wait for the page to load in milliseconds.
- Wait for XPath: The XPath to wait for before continuing. The process continue in any case once the
Wait on page load (millisec)is reached. - Javascript: The javascript to execute on the page. The javascript is executed after the page is loaded and before the shadow DOM is extracted.
- Extract Shadow DOM: Extract the shadow DOM content.
- Shadow Host(s) XPath: The XPath to the shadow host(s) to extract. If not set, the whole shadow DOM is extracted.
If set all the shadow DOM nested inside the
shadow host(s)is extracted and the content is merged in the order they appear in the page.
XML Configuration
Below is the XML configuration for this operation:
<mac-web-crawler:get-page-content doc:name="[Page] Get content"
doc:id="8f436a64-1795-42a0-9fe7-69be66db235b"
config-ref="MuleSoft_WebCrawler_Config"
url="#[payload.url]"
outputFormat="MARKDOWN"
waitOnPageLoad="2000"
waitForXPath="//results"
extractShadowDom="true"
shadowHostXPath="//results"/>Output Fields
Payload
This operation responds with a json payload.
Example
{
"title": "The MuleSoft AI Chain (MAC) Project",
"url": "https://mac-project.ai/",
"content": "The MuleSoft AI Chain (MAC) Project DocsDocsAboutAbout GitHub GitHub (opens in a new tab) Light Build powerful AI Agents with MuleSoft AI Chain Seamlessly integrate cutting-edge AI capabilities into your MuleSoft ecosystem, enabling smarter automation and enhanced decision-making. Go to Docs→ Full-powered AI Agents with MuleSoft No Code / Low Code Development MS AI Chain enables MuleSoft developers to leverage powerful AI capabilities with minimal coding. Easily configure and manage AI agents directly within Anypoint Studio, streamlining the development process. MuleSoft AI Chain Project (MAC) is OpenSource MAC Project is an open-source project empowering developers to integrate advanced AI capabilities into the MuleSoft ecosystem. Join our community to collaborate, innovate, and drive the future of technology. Leverage AI Capabilities, Seamlessly Integrated with MuleSoft Enhance your MuleSoft ecosystem with advanced AI functionalities from multiple Large Language Models. Light We Are OpenSource © 2024 The MuleSoft AI Chain Project."
}Page | Get Insights
Allows you to fetch insights from a webpage. This allows retrieve things like:
- word count on the page
- count on elements or tags such as H1, H2, DIV, P etc. You can also specify your own tags to retrieve insights by specifying these tags in the configuration of the operation.
- link structures (broken down into internal, external and reference)
- image links
Input Fields
Module Configuration
This refers to the MAC Web Crawler Configuration set up in the Getting Started section.
General
- Page URL: The webpage to fetch the insights for.
Target Content
- Tag list: An ordered list of CSS selectors (tags) for content extraction. The crawler will use the HTML content from the first selector that matches an element on the page. If there are no matches, the full HTML of the page will be extracted.
Page Load Options (WebDriver)
Page load options only applies to the WebDriver connection. They make sense only in case of dynamic content retrieval.
- Wait on page load (millisec): The time to wait for the page to load in milliseconds.
- Wait for XPath: The XPath to wait for before continuing. The process continue in any case once the
Wait on page load (millisec)is reached. - Javascript: The javascript to execute on the page. The javascript is executed after the page is loaded and before the shadow DOM is extracted.
- Extract Shadow DOM: Extract the shadow DOM content.
- Shadow Host(s) XPath: The XPath to the shadow host(s) to extract. If not set, the whole shadow DOM is extracted.
If set all the shadow DOM nested inside the
shadow host(s)is extracted and the content is merged in the order they appear in the page.
XML Configuration
Below is the XML configuration for this operation:
<mac-web-crawler:page-get-insights
doc:name="Get page insights"
doc:id="08dd9627-5220-41df-a7cf-869bff4eee91"
config-ref="MuleSoft_WebCrawler_Config"
url="#[payload.url]"/>Output Fields
Payload
This operation responds with a json payload.
Example
{
"pageStats": {
"div": 36,
"p": 6,
"reference": 0,
"internal": 7,
"external": 2,
"images": 4,
"wordCount": 147,
"h1": 1,
"h2": 0,
"h3": 4,
"h4": 0,
"h5": 0
},
"links": {
"reference": [],
"internal": [
"https://www.mac-project.ai/",
"https://mac-project.ai/docs",
"https://mac-project.ai/",
"https://mac-project.ai/docs/mulechain-ai/getting-started",
"https://mac-project.ai/docs/contribute",
"https://mac-project.ai/docs/mulechain-ai/supported-operations",
"https://mac-project.ai/about"
],
"external": [
"https://www.linkedin.com/groups/13047000/",
"https://github.com/MuleSoft-AI-Chain-Project"
],
"images": [
"https://mac-project.ai/_next/image?url=%2Flogos%2Fmulechain-project-logo.png&w=96&q=75",
"https://mac-project.ai/_next/image?url=%2F_next%2Fstatic%2Fmedia%2Fcard-1.b6224663.png&w=3840&q=75",
"https://mac-project.ai/_next/image?url=%2F_next%2Fstatic%2Fmedia%2Fcard-operations.d3098f38.png&w=1920&q=75",
"https://mac-project.ai/_next/image?url=%2F_next%2Fstatic%2Fmedia%2Fcard-1.dark.fd8b5613.png&w=3840&q=75"
],
"documents": [
],
"iframe": [
]
},
"title": "The MuleSoft AI Chain (MAC) Project",
"url": "https://mac-project.ai/"
}Page | Get Meta Tags
Allows you to retrieve metadata from a webpage, including title, description, keywords, and other SEO-related information.
Input Fields
General
- Page URL: The webpage to fetch the meta tags for.
Page Load Options (WebDriver)
Page load options only applies to the WebDriver connection. They make sense only in case of dynamic content retrieval.
- Wait on page load (millisec): The time to wait for the page to load in milliseconds.
- Wait for XPath: The XPath to wait for before continuing. The process continue in any case once the
Wait on page load (millisec)is reached. - Javascript: The javascript to execute on the page. The javascript is executed after the page is loaded and before the shadow DOM is extracted.
- Extract Shadow DOM: Extract the shadow DOM content.
- Shadow Host(s) XPath: The XPath to the shadow host(s) to extract. If not set, the whole shadow DOM is extracted.
If set all the shadow DOM nested inside the
shadow host(s)is extracted and the content is merged in the order they appear in the page.
XML Configuration
Below is the XML configuration for this operation:
<mac-web-crawler:page-get-meta-tags
doc:name="[Page ]Get meta tags"
doc:id="2cd02e46-5607-43f1-9e2b-3ce624a6a68a"
url="#[payload.url]"/>Output Fields
Payload
This operation responds with a json payload.
Example
[
{
"name": "robots",
"content": "index,follow"
},
{
"property": "og:title",
"content": "Introduction"
},
{
"name": "msapplication-TileColor",
"content": "#fff"
},
{
"name": "theme-color",
"content": "#fff"
},
{
"name": "viewport",
"content": "width=device-width, initial-scale=1.0"
},
...
]